Articolo liberamente tradotto dal blog di MongoDB: Unlocking Operational Intelligence from the Data Lake: Part 2 - Operationalizing the Data Lake
Come discusso nella prima parte, i data lake basati su Hadoop riescono a generare nuove forme di insights da diversi dataset, ma non sono progettati per offrire l'accesso in tempo reale alle applicazioni operative.
Gli utenti hanno bisogno di output di analisi da Hadoop disponibili per le loro applicazioni in tempo reale. Queste applicazioni hanno specifiche richieste di accesso che non possono esssere soddisfatte dall'HDFS, come:
Mettere insieme elaborazioni operative e analitiche su grandi volumi di dati strutturati in modo variabile su un singolo database richiede le capacità uniche di MongoDB:
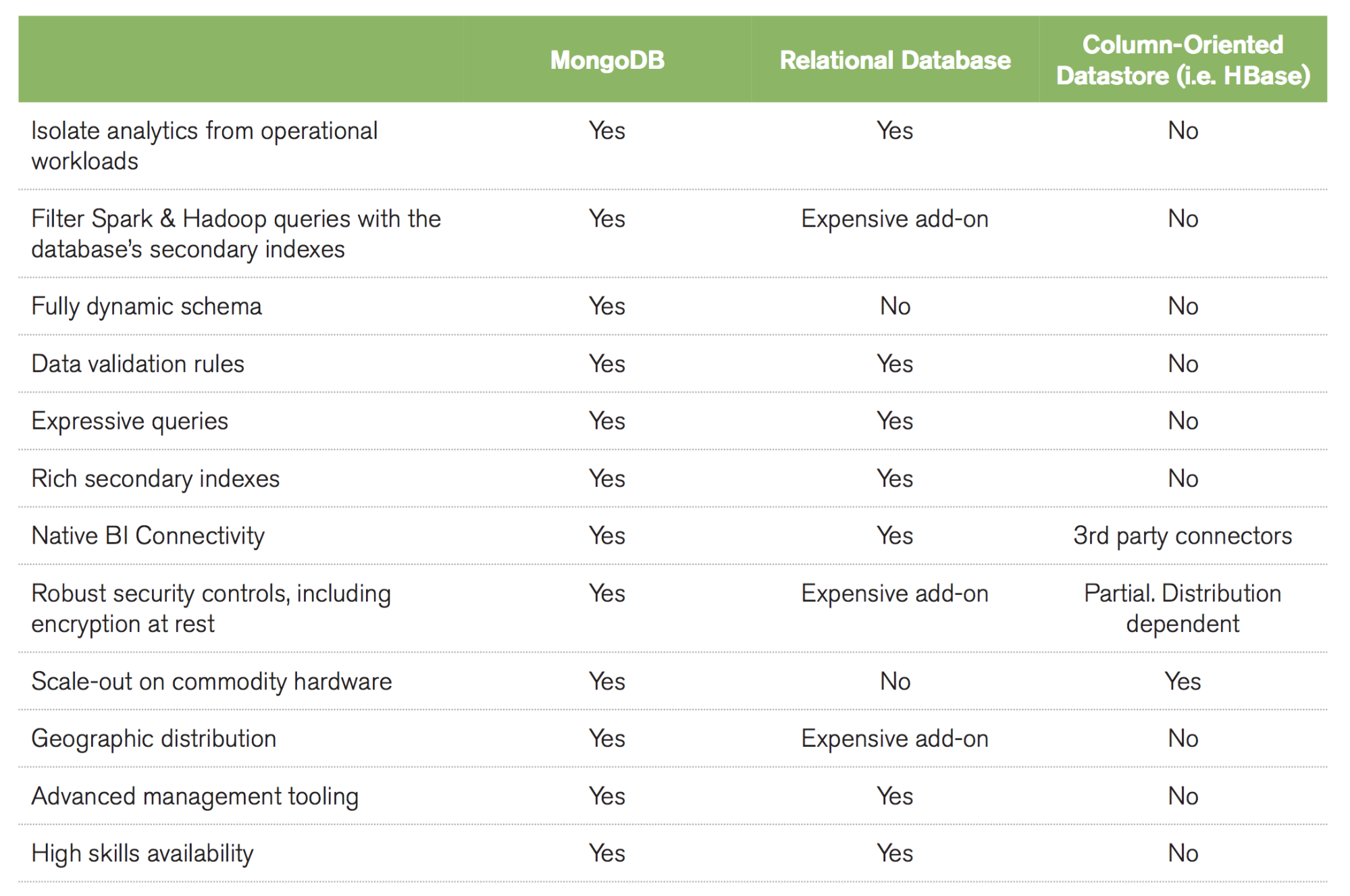
Come mostrato nella tabella, l'intelligenza operativa richiede un database ricco di features che serve come System of Record per le applicazioni online. Questi requisiti non sono sufficienti per le capacità dei semplici data-store chiave-valore o column-oriented che sono tipicamente usati per dati transitori a vita breve, o per database relazionali strutturati intorno a rigidi formati riga-colonna e architetture scale-up.
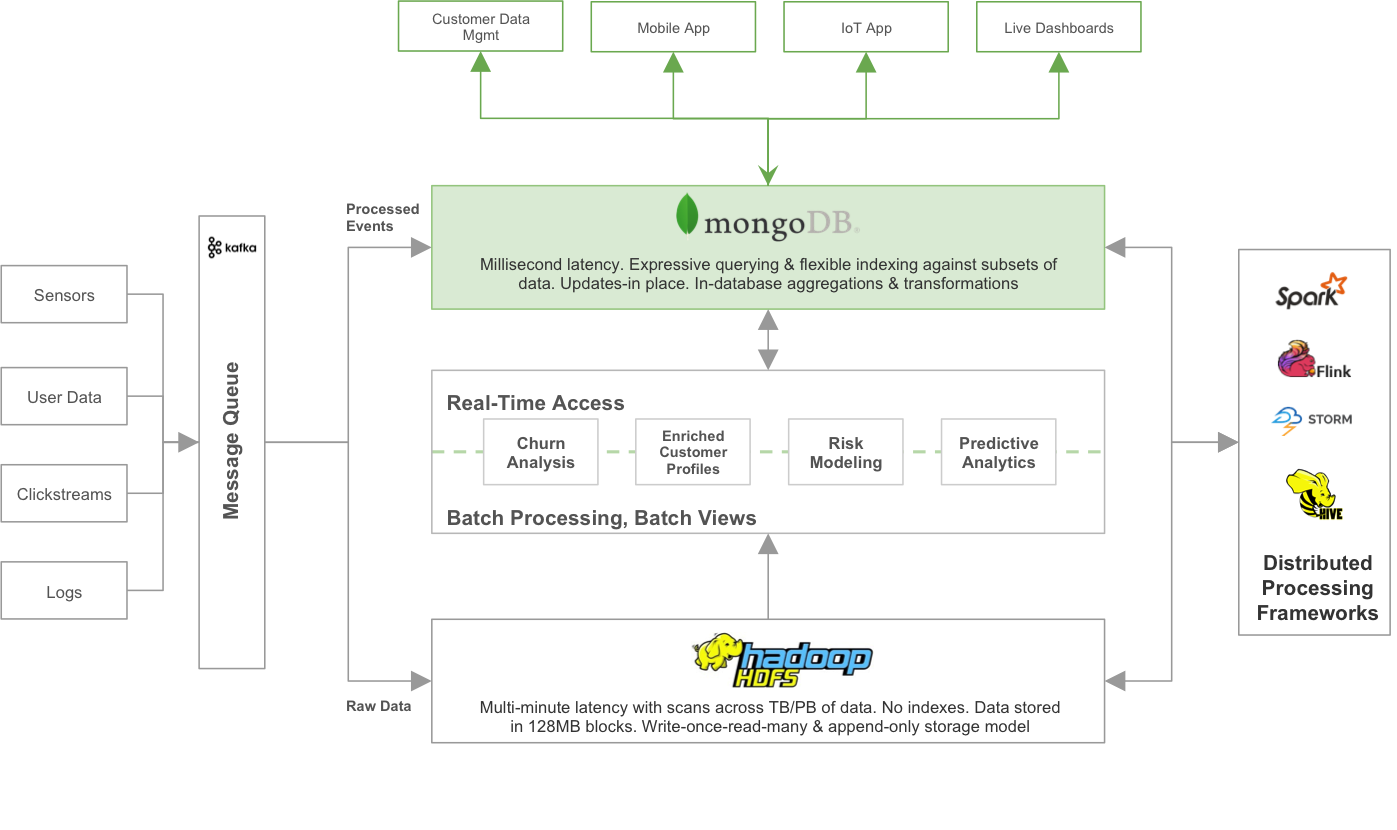
La figura mostra un pattern di progetto per integrare MongoDB con un data lake:
Come discusso nella prima parte, i data lake basati su Hadoop riescono a generare nuove forme di insights da diversi dataset, ma non sono progettati per offrire l'accesso in tempo reale alle applicazioni operative.
Gli utenti hanno bisogno di output di analisi da Hadoop disponibili per le loro applicazioni in tempo reale. Queste applicazioni hanno specifiche richieste di accesso che non possono esssere soddisfatte dall'HDFS, come:
- La risposta alle query in millisecondi
- L'accesso casuale a sottoinsiemi di dati indicizzati
- Il supporto di query espressive ad-hoc e di aggregazioni sui dati, per rendere le applicazioni online più intelligenti e contestuali.
- Aggiornare i dati in tempo reale quando gli utenti interagiscono con l'applicazione, senza dover riscrivere l'intero dataset.
Mettere insieme elaborazioni operative e analitiche su grandi volumi di dati strutturati in modo variabile su un singolo database richiede le capacità uniche di MongoDB:
- Isolamento del carico di lavoro. I replica sets di MongoDB possono essere forniti di nodi di analisi dedicati. Questo permette agli utenti di eseguire analisi simultaneamente in tempo reale e di eseguire query sui dati constantemente aggiornati, senza impattare i nodi che servono le applicazioni operative, ed evitando lunghissimi cicli ETL.
- Query espressive. Il linguaggio di query di MongoDB permette agli sviluppatori di costruire applicazioni che possono accedere ed analizzare i dati in molti modi diversi - per singola chiave, per range, per ricerca testuale, per query geo-spaziali attraverso complesse aggregazioni e job di MapReduce, elaborando le risposte in millisecondi. Le query complesse sono eseguite nativamente nel database senza dover usare ulteriori tool o frameworks di analisi ed evitando la latenza che deriva dallo spostare i dati attraverso i sistemi operativi ed analitici
- Ricchi indici secondari. Offrendo filtri veloci e accesso ai dati tramite qualunque attributo, MongoDB supporta indici composti, unici, a vettore, parziali, TTL, geospaziali, sparsi e testuali da ottimizzare in base ai requisiti di applicazioni, tipi di dati e pattern di query. Gli indici sono essenziali quando si opera su porzioni di dati, ad esempio quando si aggiorna l'analisi churn di un sottoinsieme di clienti senza dover scansionare tutti i dati.
- Integrazione di BI e Analytics. MongoDB Connector for BI permette alle aziende che usano strumenti di analisi e visualizzazione come Tableau di accedere efficientemente ai dati su MongoDB usando SQL.
- Robusti controlli di sicurezza. Estesi controlli d'accesso, auditing per l'analisi forense e criptaggio dei dati sia "in volo" che "a riposo" permettono a MongoDB di proteggere le informazioni di valore e sodddisfare i bisogni dei carichi di lavoro dei big data nelle industrie regolamentate.
- Scalabilità sull'hardware dei prodotti. MongoDB può scalare all'interno e attraverso data center distribuiti geograficamente, offrendo altissimi livelli di disponibilità e scalabilità. Man mano che il data lake cresce, MongoDB scala facilmente senza tempi di inattività o modifiche agli applicativi.
- Piattaforma di gestione avanzata. Per ridurre il TCO del data lake e il rischio di inattività dell'applicazione, MongoDB Ops Manager offre strumenti potenti per automatizzare lo sviluppo del data base, la sua scalabilità, il monitoraggio, gli alert e il disaster recovery.
- Grande disponibilità di skills. Con la disponibilità delle capacità di Hadoop citate dagli analisti di Gartner come una top challenge, è essenziale scegliere un database operativo che offra una grande talent pool. Questo permette di trovare risorse che possano velocemente costruire differenti applicazioni big data. Secondo diversi indicatori, fra cui DB Engines Rankings, 451 Group NoSQL Skills Index e il Gartner Magic Quadrant for Operational Databases, MongoDB è attualmente il database non-relazionale leader nel settore.
Come mostrato nella tabella, l'intelligenza operativa richiede un database ricco di features che serve come System of Record per le applicazioni online. Questi requisiti non sono sufficienti per le capacità dei semplici data-store chiave-valore o column-oriented che sono tipicamente usati per dati transitori a vita breve, o per database relazionali strutturati intorno a rigidi formati riga-colonna e architetture scale-up.
- I data stream entrano in una coda di messaggi pub/sub, che indirizza tutti i raw data (dati allo stato grezzo, ndt) nell'HDFS. Gli eventi processati che guidano le azioni in tempo reale, come le offerte personalizzate per un utente che sfoglia la pagina di un prodotto, o gli allarmi per la telemetria dei veicoli, sono indirizzati a MongoDB per un immediato uso da parte delle applicazioni operative.
- I framework di elaborazione distribuita come Spark o i job di MapReduce materializzano le viste batch dai dati grezzi archiviati nel data lake Hadoop.
- MongoDB espone questi modelli ai processi operativi, offrendo loro query e aggiornamenti con risposta in tempo reale.
- I framework di elaborazione distribuita possono ricalcolare i modelli analitici sui dati archiviati sia nell'HDFS che in MongoDB, passando continuamente aggiornamenti dal database operativo alle viste analitiche.
Commenti
Posta un commento